The Document Object Model (DOM) is an interface for HTML elements which represents its elements as nodes which has objects in a tree-like fashion which can be modified in a scripting fashion by JS. The HTML DOM API adds functionality for manipulating HTML elements and advanced features like web workers.
The tree root always begins at the window, where the document object is then loaded under (when the document is loaded into the window [think your browser window]). Your html elements are then loaded under the document in the HTML structure you wrote.
Try using document.body right now on a web page (via your console) and see what prints out!
This is a DOM node. It is an object and as such has specific object properties to traverse its sisters/children and modify its contents.
Some terminology: Elements which are nested within another one are called descendants. Direct descendants are called children. Siblings are nodes which are at the same nested level, i.e. share the same direct parent.
One can traverse a DOM tree node via established object properties Source
Try out some of the above or these methods and see what you can access on your HTML web page of choice.
Note: The childNodes property may seem to return an array but it is actually a collection. To loop through it we need to use a for... of loop as it does not contain the native array properties. You should still be able to use the [] syntax to access its elements though.
Exercise: Given the below HTML structure. Just from the document.body, how do we access the <p> tag?
<body>
<div>Hi!</div>
<p>
Example text
</p>
<div>End!</div>
</body>
Accessing elements directly
Instead of traversing the tree and finding the desired element, we may access elements direct via their id attribute . In fact this is a very common technique.
The most common method is to use the document.getElementById('YOURID'). You can also try the document.querySelectorAll('yourCSSSelector') which uses a CSS selector. You can also access collections from methods such as document.getElementsByClassName which return live collections which means it auto-updates as the DOM gets manipulated.
Now that we have a desired element, we can perform operations on it such as changing its styling and/or setting text!
Probably the most common thing you will see in vanilla JS is to add callback functions (handlers) to a node when an event such as a click is fired.
Once we get an node, we can get its and modify its text via the innerHTML property.
Exercise: Find a node with an ID and change its text.
We can also change the styling of a DOM node directly instead of using CSS. Think about the implications now that we can intertwine javascript with CSS! Although the better pattern is to add and remove classes to a DOM node, there may be edge cases where you want to set styling direct and manually.
Exercise: Find out how to style a node. Then learn how to add and remove classes from a node.
Conclusion
There are many other node properties you can find here in addition to many other DOM concepts. But in general this tutorial was more a conceptual exercise for you to understand how the browser loads a HTML document and how front-end libraries use these base methods to access & manipulate nodes. For example, you may realize how long-winded it is to access an element. Thus libraries such as jQuery ( $('#myDiv) versus document.getElementById('myDiv') ) have been invented to easier DOM manipulation.
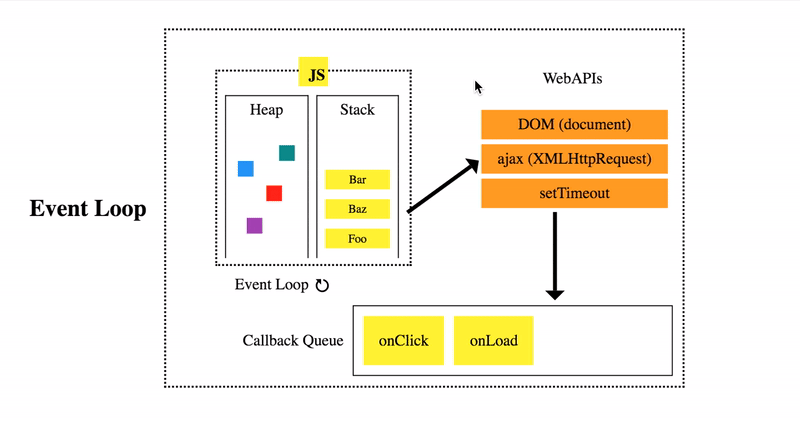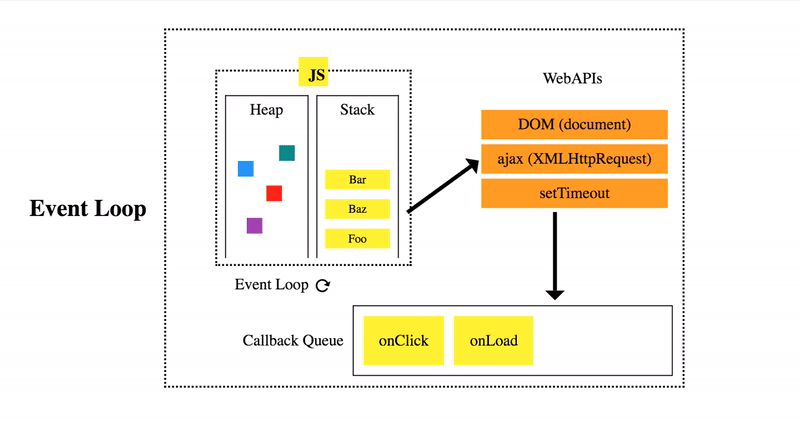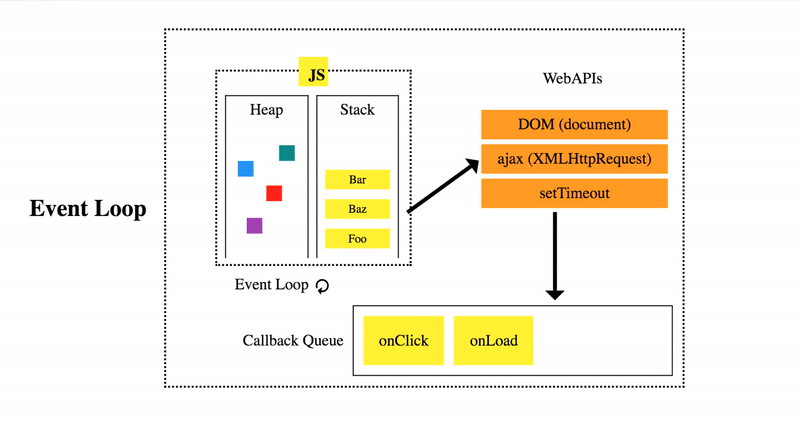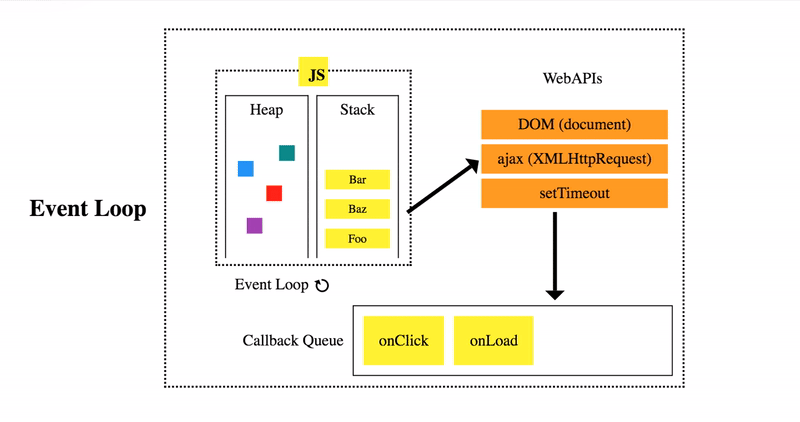
JS is single-threaded, it has one call stack and one memory heap. So it must finish the current frame in the stack before moving to the next. That is, if you have a long loop, the engine must complete the loop before going on to the next task. This approach is called synchronous (‘sync’) execution. Obviously for things like long loops we can use clever programming and efficient algorithms to not clog up the stack and delay the UX for the user. However, what about things we cannot control – like requests to 3rd-party webservices? We do not know when the response will return as we do not know how fast the server’s and client’s internet speed is. To combat this, JS engines have Web APIs (Application Programming Interfaces). During execution, those web requests are diverted to the browser’s Web APIs to be handled as to not block the main stack. Once the request is returned, the callback function (remember, a callback function is a function passed as an argument) is pushed back onto the stack. If you really want to get into the nitty gritty, you can look into event loop of JS engines. Here is a great video for understanding the architecture. If you’re really looking to be advanced, you can also look into micro- and macro-tasks (here and here). Today, we’ll take a look at what APIs are and making requests to them.
In JS. There’s one stack and one heap for execution. To prevent blocking, Web APIs can handle server requests and other tasks such that JS can incorporate async code. Once those requests are done, they get pushed to the callback queue and then the event loop pushes those callback functions get pushed to the main stack. Image credits
Application Programming Interfaces (APIs) and HTTP (HyperText Transfer Protocol)
APIs, more generally are an interface to facilitate communication between different programs. In web development, they’re almost always synonymous with externally hosted webservers that return defined values when queried with a set of parameters. That is, a client (you) sends a request with predefined variables at a URL over HTTP to a server. The server then does some calculation and responds back with a defined format (usually JSON [Javascript Objection Notation]). The preferred convention for APIs is to follow the REST architecture for making requests to servers. Usually a public API will have documentation for accessing its resources, however. Here at the BAR, we host many APIs for bioinformatic developers such as gene annotations, sequences, interaction data, expression data, and much more. For an example of a simple BAR API check out here: https://bar.utoronto.ca/eplant/cgi-bin/querygene.cgi?species=Arabidopsis_thaliana&term=AT3G24650 which returns:
The above structure is JSON which is really similar to JS objects except for double-quotes and some other rules. Once we get this data we can start immediately playing with it inside a callback function! Now you can see the power of the web programming! Imagine all the APIs you can use the combinations of those! The only downside is your app is now reliant on many outside APIs. Of course, you can also write your own APIs as an alternate to client-side calculation which I sometimes do if I feel the computation run-time is too intensive browser-side.
Note that when you go to a URL via a web browser it is almost a GET request. Meaning you are retrieving data from a web resource (almost always a web page). There are various methods in HTTP such as POST, DELETE, PATCH, and OPTIONS. But for most part you just need to know they exist and they modify the data you get back. Sometimes if the server is not set up to acknowledge that type of HTTP method, it will simply reject the request. For example, if you did a POST request to the above URL you would not get a response back. In fact, you will get an error… Remember those error codes whenever you try to upload an essay last minute? Some common HTTP codes:
200 = request OK
400 = bad request [ the server cannot understand your request format, change your query!]
401 = need authorization [ add auth code to your request ]
403 = forbidden
404 = not found [ server cannot respond at the URL requested ]
500 = server error
Whenever you submit a web request you will always get a status code above which can be useful during debugging.
Async programming (promises)
Now I will show you how to apply these principles and use those Web APIs. First you should really understand what goes on during an async call to a webservice. What would you expect would happen based on your knowledge in the intro based on the following JS code:
console.log('start');
fetch('http://dummy.restapiexample.com/api/v1/employees')
.then(res=>res.json())
.then(data=>(console.log('where will I print?', data)))
.catch(err=>(console.log('error!', err)))
console.log('finish!');
Copy-and-paste this code into your dev tools, run it and see what happens. By the way, I am using ES6 arrow functions instead of the long-form.
The above uses the promises implementation of making web requests. If you want a historical background for why we use promises, look up ‘callback hell’. Anyways, browsers (and nodeJS) have the fetch keyword/function Web API to make requests to APIs. Fetches only need a URL as seen above to start making GET requests. From there, the Web API is cast off as seen above to work its magic. Fetches return promises. Promises can either resolve (status 200) or reject (server not found, other errors, etc.). When they resolve, they move onto the ‘closest’/next then handler to execute the callback code inside that then block (i.e. res => res.json() will be executed after our fetch is done). NOTE: JSON data MUST be parsed first with json() before performing tasks on it. You will then get your data in object literal form.
then handlers also return promises which allows promise chaining like seen above after we execute some code after res.json(). After code execution in the handler, it will return the return value, OR another promise’s result (usually after some delay of course) after resolution/rejection. Promise chaining will always receive the resolved/return value from the previous promise in the chain assuming success. That’s how we got ‘data’ from the then handler.
A then handler will ALWAYS return a promise. From here, code will be executed in the callback. Once done, it will either return a value to the next then hander, throw an error to be caught, or return a promise waiting to be resolved/rejected. Source: javascript.info
If a promise does NOT resolve, it rejects such that execution flow goes to the ‘closest’ catch handler in the chain. Put some weird characters in the above URL, what happens, what prints? Should we have multiple catches in our promise chain, what could its utility be?
Should we put synchronous code in another then block or perform all of it inside one block? I.e. let’s say we get some gene sequence data and want to calculate its codon sequence. From there, we want to see if it matches our domains of interest. Why or why not? I.e. should we chain it to be something like this:
fetch('genesequenceURL')
.then(res=>res.json())
.then(data=>{
const codonSeq = calculateCodons(data)
return codonSeq
})
.then(codonSeq=>{
console.log('does is it have my domains', getDomains(codonSeq, 'zincfinger'));
})
If we are making multiple API calls, and one is dependent on another (say we need a gene symbol (via an API) to get its sequence), how would we make a promise chain to do such a thing?
Look up how we would make a POST request instead of a GET request via fetch, try it in your browser
Tip: Make sure your HTTP headers are set correctly during any non-GET request.
What is the utility of Promise.all ? Google the function (Google is a web dev’s best friend).
For UX purposes, say an API fetch rejects. Instead of printing errors, what is a user friendly way of displaying a failed API call?
For those advanced, look up async/await. I personally use async/await over classical promises but it is really just syntactical sugar.
This tutorial series covering javascript assumes you have prior scripting knowledge and refines your ability to think in a web-based/javascript way. That is, some syntax and basic programming paradigms will be covered but will not be the focus on this series. JavaScript, its accompanying libraries and runtime environments have come a long way but in this series I will teach you the foundations of vanilla browser-based JavaScript to help you understand the intricacies of this language. It’s also much faster to get going!
JavaScript (JS or js) is one part of the successor to Flash-based websites. It is the language and logic that allows for dynamic web-pages to come alive (although CSS can do some fantastic things on its own) such as instant messaging, sending a form, making a payment, and much more. Think of it as the painter of the canvas with constructed rules (logic/syntax) on how to paint and repaint on the webpage. She can also erase the some of the webpage (i.e. delete HTML elements) directly. It was created by Brendan Eich in the 90s in 10 days in the spirit of Java but has little to do with Java, in fact classes were not a thing until recently.
Fundamentals and Architecture of the language:
High level language that was made for browsers, does not typically have access to CPU/RAM
Weakly-typed, i.e. you don’t need to declare what a type a variable is
All numbers are floating points FYI
Prototypal inheritance versus your traditional class-based inheritance (advanced, but FYI)
Can be thought of as interpreted but there are just-in-time compilers and modern JS bundlers that ‘transpile’ JS code (advanced)
Memory garbage collection automatically handled
Functions are pass-by-value and pass-by-reference(hotly debated, let’s not argue!)
Single threaded, but has asynchronous control via ‘Web-APIs’ (important, covered later)
Libraries (or modules in other languages) are often UI-based due to the web-nature of JS
See here or here for some more differences and history
JS Basics
Before we start you should code-along with either your browser dev tools console (press F12 on Chrome) or use something like REPL which hosts a browser-based javascript runtime for you.
PS: Useconsole.log("my text", var1); to debug for now
Before you begin, you should know… Just like python there are differences in testing equivalency in JS, most prominently displayed by the ‘==‘ and ‘===‘ operator. == uses type coercion to try to figure out if two values are the same for a primitive, can you think of an example of a string and number (psst, test it!) that returns true using ==? === however is more strict and tests for type and value equivalency. For objects (i.e. non-primitives), both operands are treated the same and reference checks are made.
var imANum = 5.01;
var alsoaNum = 5;
var string = "yolo";
let string1 = 'FOMO';
let templateString = `I ${string} because I got ${string1} !!!111!`;
const justABoolean = true;
const hiImNull = null;
var wellImUndefined = undefined;
var obj1 = { country: "Mozambique", continent: "Africa" }
var obj2 = { country: "Azerbaijan", continent: "Asia" }
var obj2 = { country: "Azerbaijan", continent: "Europe" }
const sym1 = Symbol("hi");
const sym2 = Symbol("hi");
A few things…
Notice how arrays/lists (we call them arrays in JS, they have list-like and array-like properties) is not a type unlike other languages? Arrays in are objects in JSland with special properties given by their prototype chain such as ‘length’.
Functions are also objects. First-class objects in fact which means you can play around with functions just like a typical variable! For example you can pass a function as an argument to another function (the passed function called a callback function).
undefined usually means that the variable has not be assigned a value. null is almost always an assignment value.
We use typeof operator to identify the object type. Try it!
For those who are familiar with Python (i.e. all of you), fill in the blanks: A JS object can be analogous to a ______________ (python type) and has pairs of __________ (property names) and ___________ (property values).
Can we figure out which data types return truthy or falsy values?
Hint: Conditionals are written like so if (2 > 1) { console.log('true') }
I’m actively listening check-up: Should two empty arrays assigned independently return true when they’re checked for equivalency via ‘===‘?
What does templateString print out?
These are template strings and are much more terse way of interpolating variables than the old-school way of concatenating strings together.
Symbols are an esoteric primitive data type are unique identifiers, it is mostly used for object property names.
Notice how we declare our variables with ‘var‘, ‘const‘ or ‘let‘?
var is a classical way to declare variables that is either globally or functionally scoped; it can be re-assigned to another value
let is similar however is lexically scoped (fancy way of saying the variable is scoped within a curly braces ‘{ }’)
There’s also some differences in how each variable is “hoisted” inside a function to be used; var variables are brought to searched for and hoisted to the top of the function
Can you think of this local vs functionally scoping where this can be an issue? Hint: Think of for loops, for those are who are advanced, look up the ‘closure issue with var’
const is the most unique declaration in that the variable value cannot be changed by direct assignment (what do I mean by this?); it has similar scoping rules as ‘let‘. See how I reassigned obj2 easily but can you try reassigning justABoolean to false?
Up Next
This week’s workshop may have been a bit simple as some of you may already have experience scripting and simply see it as a programming syntax-workshop but soon we will dive into the intricacies of JS and how it operates the browser via the Document Object Model (DOM) !