Asynchronous Javascript and XML (AJAX)
Introduction
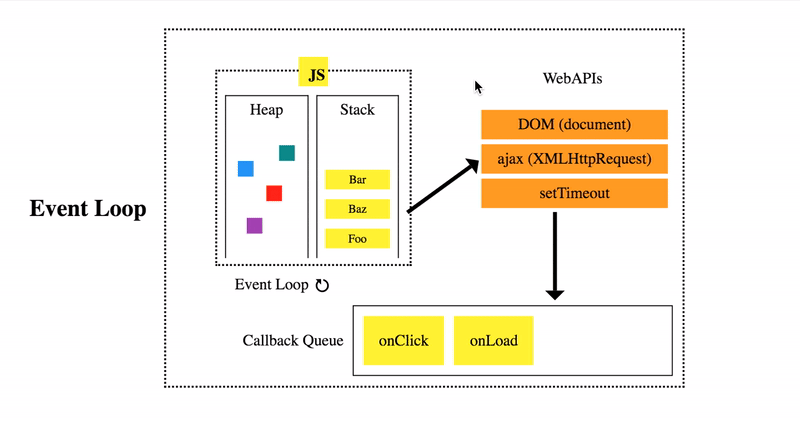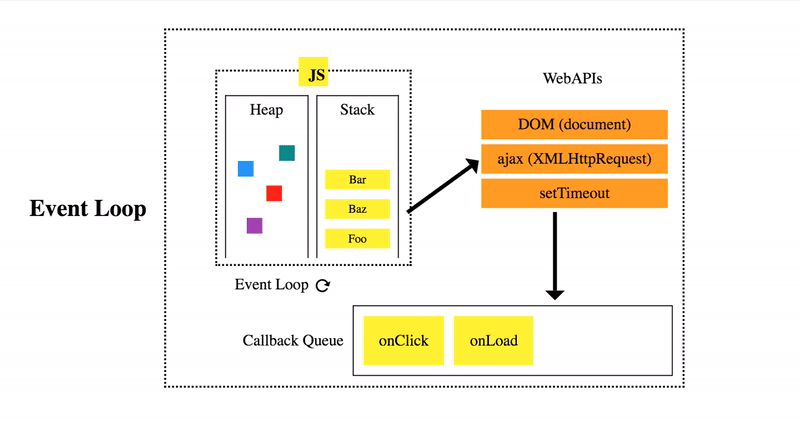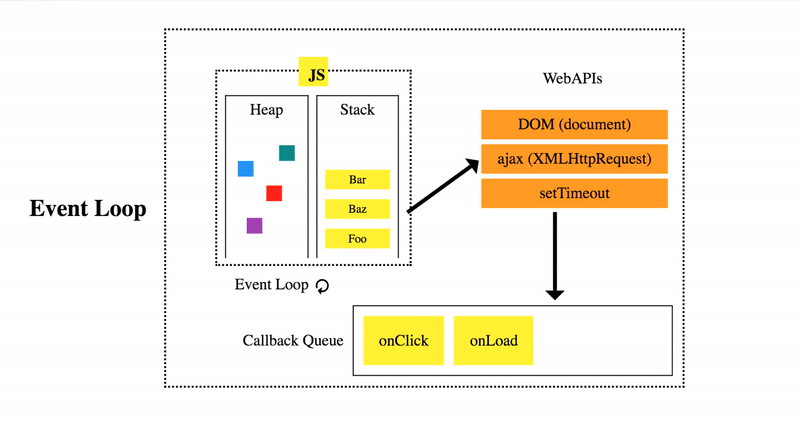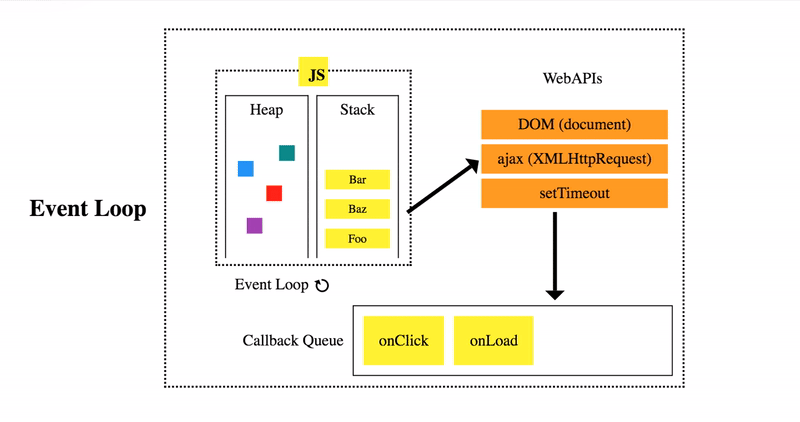
JS is single-threaded, it has one call stack and one memory heap. So it must finish the current frame in the stack before moving to the next. That is, if you have a long loop, the engine must complete the loop before going on to the next task. This approach is called synchronous (‘sync’) execution. Obviously for things like long loops we can use clever programming and efficient algorithms to not clog up the stack and delay the UX for the user. However, what about things we cannot control – like requests to 3rd-party webservices? We do not know when the response will return as we do not know how fast the server’s and client’s internet speed is. To combat this, JS engines have Web APIs (Application Programming Interfaces). During execution, those web requests are diverted to the browser’s Web APIs to be handled as to not block the main stack. Once the request is returned, the callback function (remember, a callback function is a function passed as an argument) is pushed back onto the stack. If you really want to get into the nitty gritty, you can look into event loop of JS engines. Here is a great video for understanding the architecture. If you’re really looking to be advanced, you can also look into micro- and macro-tasks (here and here). Today, we’ll take a look at what APIs are and making requests to them.
Application Programming Interfaces (APIs) and HTTP (HyperText Transfer Protocol)
APIs, more generally are an interface to facilitate communication between different programs. In web development, they’re almost always synonymous with externally hosted webservers that return defined values when queried with a set of parameters. That is, a client (you) sends a request with predefined variables at a URL over HTTP to a server. The server then does some calculation and responds back with a defined format (usually JSON [Javascript Objection Notation]). The preferred convention for APIs is to follow the REST architecture for making requests to servers. Usually a public API will have documentation for accessing its resources, however. Here at the BAR, we host many APIs for bioinformatic developers such as gene annotations, sequences, interaction data, expression data, and much more. For an example of a simple BAR API check out here: https://bar.utoronto.ca/eplant/cgi-bin/querygene.cgi?species=Arabidopsis_thaliana&term=AT3G24650 which returns:
{
"id": "AT3G24650",
"chromosome": "Chr3",
"start": 8997370,
"end": 9001063,
"strand": "+",
"aliases": ["ABI3", "AtABI3", "SIS10"],
"annotation": "AP2/B3-like transcriptional factor family protein"
}
The above structure is JSON which is really similar to JS objects except for double-quotes and some other rules. Once we get this data we can start immediately playing with it inside a callback function! Now you can see the power of the web programming! Imagine all the APIs you can use the combinations of those! The only downside is your app is now reliant on many outside APIs. Of course, you can also write your own APIs as an alternate to client-side calculation which I sometimes do if I feel the computation run-time is too intensive browser-side.
Note that when you go to a URL via a web browser it is almost a GET request. Meaning you are retrieving data from a web resource (almost always a web page). There are various methods in HTTP such as POST, DELETE, PATCH, and OPTIONS. But for most part you just need to know they exist and they modify the data you get back. Sometimes if the server is not set up to acknowledge that type of HTTP method, it will simply reject the request. For example, if you did a POST request to the above URL you would not get a response back. In fact, you will get an error… Remember those error codes whenever you try to upload an essay last minute? Some common HTTP codes:
- 200 = request OK
- 400 = bad request [ the server cannot understand your request format, change your query!]
- 401 = need authorization [ add auth code to your request ]
- 403 = forbidden
- 404 = not found [ server cannot respond at the URL requested ]
- 500 = server error
Whenever you submit a web request you will always get a status code above which can be useful during debugging.
Async programming (promises)
Now I will show you how to apply these principles and use those Web APIs. First you should really understand what goes on during an async call to a webservice. What would you expect would happen based on your knowledge in the intro based on the following JS code:
console.log('start');
fetch('http://dummy.restapiexample.com/api/v1/employees')
.then(res=>res.json())
.then(data=>(console.log('where will I print?', data)))
.catch(err=>(console.log('error!', err)))
console.log('finish!');Copy-and-paste this code into your dev tools, run it and see what happens. By the way, I am using ES6 arrow functions instead of the long-form.
The above uses the promises implementation of making web requests. If you want a historical background for why we use promises, look up ‘callback hell’. Anyways, browsers (and nodeJS) have the fetch keyword/function Web API to make requests to APIs. Fetches only need a URL as seen above to start making GET requests. From there, the Web API is cast off as seen above to work its magic. Fetches return promises. Promises can either resolve (status 200) or reject (server not found, other errors, etc.). When they resolve, they move onto the ‘closest’/next then handler to execute the callback code inside that then block (i.e. res => res.json() will be executed after our fetch is done). NOTE: JSON data MUST be parsed first with json() before performing tasks on it. You will then get your data in object literal form.
then handlers also return promises which allows promise chaining like seen above after we execute some code after res.json(). After code execution in the handler, it will return the return value, OR another promise’s result (usually after some delay of course) after resolution/rejection. Promise chaining will always receive the resolved/return value from the previous promise in the chain assuming success. That’s how we got ‘data’ from the then handler.

If a promise does NOT resolve, it rejects such that execution flow goes to the ‘closest’ catch handler in the chain. Put some weird characters in the above URL, what happens, what prints? Should we have multiple catches in our promise chain, what could its utility be?
Promises resources:
Some understanding questions:
- Should we put synchronous code in another
thenblock or perform all of it inside one block? I.e. let’s say we get some gene sequence data and want to calculate its codon sequence. From there, we want to see if it matches our domains of interest. Why or why not? I.e. should we chain it to be something like this:
fetch('genesequenceURL')
.then(res=>res.json())
.then(data=>{
const codonSeq = calculateCodons(data)
return codonSeq
})
.then(codonSeq=>{
console.log('does is it have my domains', getDomains(codonSeq, 'zincfinger'));
})- If we are making multiple API calls, and one is dependent on another (say we need a gene symbol (via an API) to get its sequence), how would we make a promise chain to do such a thing?
- Look up how we would make a POST request instead of a GET request via fetch, try it in your browser
- Tip: Make sure your HTTP headers are set correctly during any non-GET request.
- What is the utility of
Promise.all? Google the function (Google is a web dev’s best friend). - For UX purposes, say an API fetch rejects. Instead of printing errors, what is a user friendly way of displaying a failed API call?
- For those advanced, look up async/await. I personally use async/await over classical promises but it is really just syntactical sugar.